在人工智能飞速发展的当下,推理场景对计算芯片的性能提出了极高要求。就在此时,大带宽可重构数据流芯片应运而生,以突破性技术打破传统桎梏,为推理场景带来了全新解决方案。而国产自主研发的 “夸父芯片”,更以 “追光者” 之姿,为人工智能基础设施的可持续发展注入强劲动能。

以“大带宽”与“可重构”破解算力瓶颈

这种芯片的大带宽特性,就好比高速公路的多车道。传统芯片数据传输时,像一条狭窄的单车道公路,速度慢还易拥堵,难以满足高速数据流转的需求;而可重构数据流芯片,凭借多层内存叠加技术构建起 “八车道高速公路”,让数据高速、顺畅传输,大幅提高数据处理效率,解决了数据传输的 “拥堵难题”。
推理场景应用:数据交互无需等待
在推理场景中,大带宽的优势十分显著。以图像识别推理为例,当需要对成百上千张图片进行实时分析时,传统芯片常因数据读取迟缓,陷入 “走走停停” 的窘境;可重构数据流芯片凭借大带宽,能将图像数据瞬间输送至计算单元,如同高速行驶的汽车快速抵达目的地,既提升速度,更保障精度。对于当前火热的大模型推理应用,它更是展现出独特优势——大带宽可让不同用户的问题同时进入计算单元,并行进行 Transformer 计算打分,让每一次交互都无需等待,大幅提升响应效率。

可重构特性:真正实现 “一芯多用”
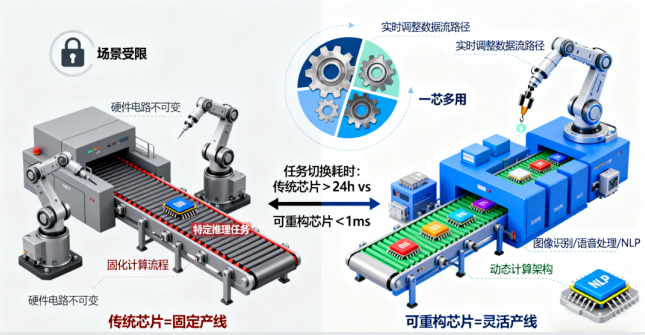
此外,这类芯片还具备可重构特性,宛如灵活多变的“工厂生产线”。传统芯片可比作固定生产线,一旦确定生产流程,便只能生产固定产品,缺乏灵活性;而可重构数据流芯片可根据不同推理任务,快速调整自身计算架构,就像工厂能迅速改变生产线生产不同产品,大大提高了芯片对各类复杂推理任务的适应性。这种灵活性,让芯片不再受限于单一场景,真正实现 “一芯多用”,从容应对复杂多变的推理任务。
市场前景与能耗优势
能耗突破:缓解 “高能耗困境”
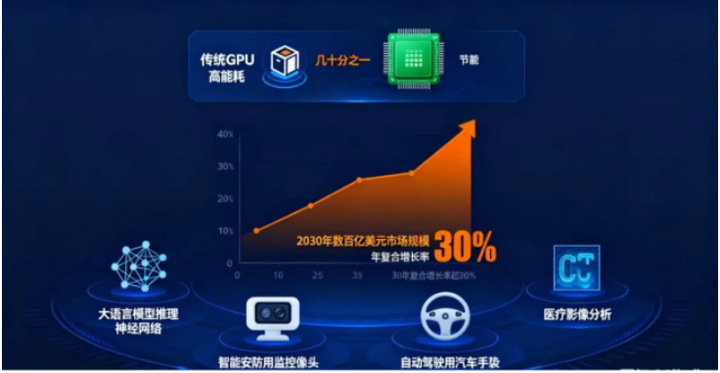
市场对这一技术的期待,早已超越概念层面——核心原因之一,便是它对‘高能耗困境’的突破性解决。马斯克曾预言:“如果英伟达的技术架构不升级,5 年后算力将会消耗一个欧洲国家全年的耗电量,如果要达成 AGI,需要数颗目前太阳能够给地球提供的能量。” 而大带宽可重构数据流芯片的能耗,仅为传统 GPU 的几十分之一,恰好为解决 “能耗焦虑” 提供了最优解。
市场预测:2030 年市场规模有望达数百亿美元
预计未来几年,随着人工智能推理应用在各领域不断拓展,可重构数据流芯片的市场规模将呈爆发式增长。到 2030 年,其市场规模有望达到数百亿美元,年复合增长率预计超 30%。尤其在大语言模型推理、智能安防、自动驾驶、医疗影像分析等对推理性能要求极高的领域,可重构数据流芯片将拥有广阔应用空间,它必将成为不可或缺的核心力量。

国产夸父芯片核心优势与特点
1、自主创新
在这片充满机遇的蓝海中,一支深耕可重构数据流芯片架构多年的中国团队,正以自主创新书写着属于国产芯片的篇章。他们研发的 “夸父芯片”,是首颗基于国产通用工艺、拥有完全自主知识产权的大算力可重构数据流芯片,从设计到制造,每一步都烙印着 “中国创造” 的印记,在关键技术指标上更是展现出超越期待的实力。

2、能效表现
谈及算力与功耗的平衡,夸父芯片优势突出,堪称“能效典范”。其单芯片具备 256TOPS-512TOPS 的强大算力,能满足复杂的人工智能计算需求,无论是大规模数据处理,还是深度神经网络的复杂运算,夸父芯片都能轻松应对。而在功耗方面,它仅需50瓦-75瓦,算效可达每瓦 10TOP 以上。

对比国内某厂商最新推出的 91xx 芯片,夸父芯片功耗可降至其六分之一,算力却能达到其 60%-75%。这就像传统高能耗设备经升级改造后,用极少能源消耗就能完成同等甚至更多工作量,大幅降低使用成本与散热压力,对于数据中心等大规模应用场景,长期运行可节省巨额电力成本。
3、成本优势
成本优势,更是夸父芯片打开市场的 “金钥匙”。与国内最先进的 91xx 芯片相比,夸父芯片综合研发成本仅为其十分之一。在芯片制造领域,成本始终是影响产品普及与市场竞争力的重要因素。

夸父芯片凭借国产通用工艺,在原材料采购、生产流程优化等方面发力,有效降低成本。这使得采用夸父芯片的人工智能产品在市场定价上更具灵活性,无论是追求高性能低价格的中小企业,还是大规模部署人工智能设备的大型企业,夸父芯片都能帮助他们降低硬件成本,提升利润空间。
4、架构优势
此外,夸父芯片的可重构数据流架构赋予其强大的任务适应性,就像多功能工具可根据不同任务需求灵活调整工作模式。在图像识别、自然语言处理、智能安防等多种人工智能推理场景中,夸父芯片都能通过重构自身架构,快速适配不同算法和模型,以高效方式完成计算任务,这是许多传统固定架构芯片难以比拟的优势。
5、夸父芯片研发背景与未来展望
值得关注的是,研发夸父芯片的团队近期已加入厦门某电子公司,该公司首席科学家孙唐的评价,道出了这一架构的核心价值:“夸父芯片的 SRDA(软件定义可重构架构)相比 DSA(领域定制)架构和 GPGPU(通用计算)架构的 AI 推理处理器,具有计算功耗效率十倍百倍的提升潜力,是未来大模型算力普惠化基础设施的一个重大创新。”

为了让更多人理解这份优势,他还做了一个生动比喻: “这个架构能给 AI 计算的每个处理专家专门配备搬运工和记录员,干活时能动态规划一条流水线,把流水线附近最适合的专家们以最短距离聚在一起,像击鼓传花似的把活干了;剩下的专家们因为有记录员和搬运工,就能闭上眼休息,不用时时刻刻紧张等待命令,从而极大节省总体功耗和调度的资源消耗。而 DSA 架构缺了听专家调令的搬运工,专家都得听 CPU 的,相当于一个 CEO 直接管理成百上千人,根本管不过来,若分层下达指令,资源开销和延迟至少翻三番。GPGPU 架构则不让专家休息,每个专家都得时刻待命,因为缺少记录员,所有数据只能边传递边加工、‘阅后即焚’,导致搬运工也得全速运转,没有一个能空下来休息的机会。”据了解,夸父芯片将于 2026 年下半年正式与公众见面,当这颗凝聚着国产智慧的芯片落地,它将以 “高能效、低成本、高灵活” 的优势,为 AI 推理场景带来全方位革新。当它真正融入人工智能的基础设施网络,必将成为照亮人工智能可持续发展之路的 “一束光”!