

《夸父大算力推理芯片可行性报告 0917.docx》(以下简称 “报告”)系统论证了基于 SRDA(可重构数据流)架构的夸父大算力推理芯片的技术可行性、市场前景与实施路径,明确其为突破 AI 算力 “存储墙”、填补国产高端推理芯片缺口的关键方案,核心内容梳理如下:
一、研究背景:AI算力需求激增下国产芯片机遇与挑战
报告指出,当前 AI 产业进入大模型驱动的新纪元,算力已成为核心驱动力:
算力需求指数级增长
据麦肯锡预测,2025 年全球计算力规模将突破 300EFLOPS,中国智能算力规模预计达 1037.3EFLOPS,但供需缺口仍达 35%,高端算力缺口尤为突出;
国产芯片差距与突破方向
华为昇腾、百度昆仑芯等国产厂商虽有进展,但生态建设滞后(超 70% 开发者因 “生态迁移成本高” 放弃国产方案),且传统冯・诺依曼架构面临 “存储墙”(如 GPT-4 训练中计算资源利用率仅 40%-50%),底层架构创新成为破局关键
SRDA 架构的核心价值
以 “数据流” 为第一性原理,通过硬件直接映射 AI 计算图数据依赖关系,减少数据移动距离与频率,从芯片、集群、系统级重构 “计算 - 存储 - 通信” 范式,解决传统架构瓶颈。
二、技术基础:SRDA架构的三层突破与性能优势
SRDA 架构核心设计理念
报告明确 SRDA 架构专为 AI 计算设计,核心特征包括:1、以数据流为中心,替代传统 “控制流” 指令驱动,减少冗余数据移动;2、系统级可重构,从芯片到集群支持 “软件定义数据流”,适配张量并行、专家并行等任务模式;3、软硬件超融合,编译器深度感知硬件特性,实现计算图高效映射;4、极简高效,剥离通用处理器复杂控制逻辑,专注 AI 核心操作(如张量运算)。
关键技术突破
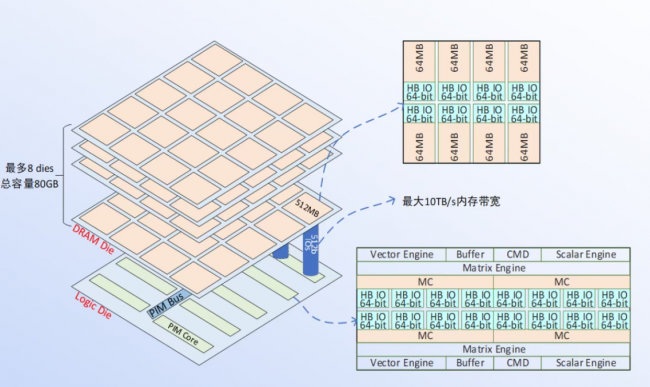
芯片级:重塑硬件交互
在科技浪潮汹涌澎湃的当下,人工智能已成为驱动各行业变革与创新的核心力量。为进一步推动人工智能技术从实验室走向市场,促进产学研深度融合,人工智能产学采用可重构数据流电路,硬件利用率提升 30%-50%;计算单元绑定私有 3D-DRAM(带宽超 10TB/s、延迟<10ns),内存访问功耗降 40%+;新增专用通信模块,通信延迟从毫秒级压至微秒级,集群算力利用率提至 60%+。研融合发展峰会,即将震撼登场。
集群级:构建无缝算力网
打破节点边界,支持 “内存语义通信”,跨节点调度张量切片延迟降 50%+;网络层内置 AI 驱动带宽分配算法,MoE 模型训练中通信带宽利用率提 30%+。
系统级:软硬件协同优化
编译器自动优化计算顺序与数据路径,Stable Diffusion 端到端推理时间缩 20%+;算子开发周期从 “周级” 压至 “小时级”,企业迁移大模型成本降 80%+。
三、市场分析:推理市场爆发为SRDA芯片提供增量空间

需求驱动
全球数据量年增 61%(IDC 预测 2025 年达 175ZB),传统架构能效提升(年增 15%)无法匹配,SRDA 架构单位能耗数据处理能力提升 10-100 倍,成为填补 “算力缺口” 的关键;同时 CXL 协议普及推动 SRDA 与 CPU/GPU 协同生态成熟。
市场规模预测:
全球市场:2022-2032 年 AI 推理业务营收 CAGR 达 48%,2032 年预计达 169 亿美元;全球可重构数据流芯片市场中,2028 年云端数据中心规模将达 420 亿美元(CAGR 63.2%),边缘计算达 145 亿美元(CAGR 58.7%)。中国市场:IDC 预测 2028 年中国加速服务器市场规模达 253 亿美元(2024-2028 年 CAGR 超 20%),非 GPU 服务器占比将接近 50%;2025 年中国 AI 服务器出货量预计达 48.8 万台,推理型服务器占比将逐步超越训练型。
竞争格局
国际层面: Moonquest AI(3D 堆叠工艺)、三星(HBM-PIM 芯片)、Groq(功能切片微架构)为主要竞争者,但 SRDA 架构在低功耗、可重构性上更适配推理场景;
国内层面:当前以 ASIC GPU 为主,SRDA 架构凭借能效优势,将成为未来 AI 推理芯片核心竞争者。
四、可行性评估:技术、经济、供应链三重保障
技术可行性
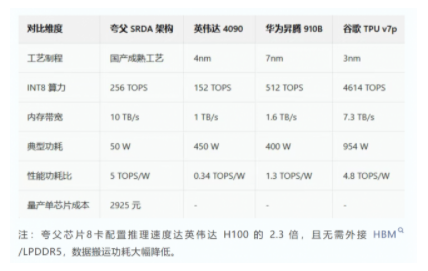
核心规格:集成多核 CPU、8K@60fps 编解码器、高能效比 NPU、80GB 3D DRAM,支持 PCIe/UCIe 扩展,实现 5TOPS/W 能效;
架构设计:3D 堆叠方案(逻辑芯片 + 1 - 多层 3D DRAM),支持 INT2/4/8 与 FP4/8/16 混合精度运算,兼容 AWQ/GPTQ 等量化方案;
工具链:自研 KF.Studio 工具链,实现 “网络解析 - 模型压缩 - 部署优化” 一键式流程,适配 PyTorch/TensorFlow,90%+ 常用算子自动化映射。
经济可行性
研发投入:合计 10460 万元(含设备、IP 授权、流片封测、人力等);
量产成本:单芯片成本 2925 元(含 DRAM Die、逻辑 Die、封装测试),远低于英伟达 H100(3 万美金 / 卡),单位算力成本较专用 AI 芯片低 30%+。
供应链可行性
采用国产成熟工艺,3D DRAM、3D NAND flash、先进封装等关键环节均为国产方案,70%+ 国产化率,关键材料备选供应商≥3 家,规避海外先进制程限制,供应链中断风险降低 60%。
五、风险与对策:全维度管控项目风险
技术风险
工艺制程落后:与国产代工厂深度合作,定制工艺模块(如优化金属互联层),辅以电路设计创新(冗余设计、纠错编码);
低 bit 量化精度损失:硬件增加动态精度切换模块,算法开发自适应量化补偿机制,与框架合作集成量化感知训练工具;
工具链适配难:联合高校开发强化学习调度算法(存算单元利用率提至 85%+),研发调试探针缩短故障定位时间,推出框架适配插件实现模型自动转换。
市场风险
国际竞争压力:加大大模型推理优化与能效提升投入,构建开发者生态,开拓细分市场;
客户信任不足:与行业标杆客户开展联合测试,参与行业标准制定,树立品牌形象;
需求动态变化:建立市场调研团队,采用敏捷开发模式,快速调整研发方向。
六、实施路径与商业化2027 年首发5年营收破 64 亿
技术研发路线
短期(1 年内):完成验证芯片开发,涵盖前端设计(IP 集成、RTL Freeze)、前端验证(子模块 / 全流程后仿)、后端实现(试流 / 流片准备)、封装设计与工具链基础功能开发;
长期(3 年内):深化可重构技术,优化低精度计算能力,推出算力超 1000 TOPS 的芯片,实现 PB 级本地存储与 EB 级全局寻址。
商业化策略
客户渗透:3 年完成 2 家互联网大厂试点(单集群≥1000 片),3-5 年覆盖 8 个行业,5 年全球边缘计算市占率达 12%;
营收预测:2027 年推出首批产品,2027-2031 年累计营收预计 64 亿元,稳定量产阶段毛利率 50%-70%,累计利润 44.7 亿元。
报告核心结论指出,夸父芯片在能效比(较传统架构提升 3-5 倍)、成本(单位算力成本低 30%+)、供应链(国产化率 70%+)上形成综合优势,2025-2027 年为 SRDA 芯片成为 AI 服务器标配的关键窗口期,预计 2026 年全球 AI 服务器 SRDA 搭载比例突破 10%,2027 年升至 20%。
未来,SRDA 架构将结合 UCIe 2.0 协议与 3D 堆叠技术,构建全域算力池;同时以 RISC-V 为根基推进开源生态,深化与主流 AI 框架适配,推动国产算力从 “跟跑” 向 “领跑” 跨越。












