随着DeepSeek效应持续让AI产业巨震,其在提供出色性能的基础上,降低了对于算力的需求,可使AI更高效、更低成本地部署在端侧设备,既而推动AIoT从“万物互联”迈向“万物智联”的同时,也为边缘AI“主力军”AI PC的端侧部署大模型提供了全新的解题思路。
据IDC预测,AI PC在中国PC市场中新机的装配比例将在未来几年中快速攀升,将于2027年达到85%,成为PC市场主流。市场总规模将从2023年的3900万台增至2027年的5000万台以上,增幅接近28%。
众所周知,端侧大模型的快速演变对AI芯片性价比和适配能力提出了更高的要求,AI PC中的AI生成任务对计算资源和处理能力的要求不尽相同,需要从以通用计算为核心的计算架构向更加高性能的异构AI计算架构升级,让CPU、GPU和NPU等不同的计算单元“各司其职”协同作战,赋能AI PC增强的生成式AI体验。在这一过程中,AI芯片重任在肩,而究竟哪类芯片能担当重任呢?

作为PC界的龙头,联想给出了自己的答案。在2025年3月3日在西班牙巴塞罗那的MWC Barcelona2025盛会上,联想展示了全面升级的AI PC。新款AI PC首次采用国内珠海市芯动力科技有限公司基于可重构并行处理器RPP的AzureBlade M.2加速卡,并将其命名为dNPU,不仅显著提升了推理速度和整体性能,让系统运行更加流畅,而且还显著降低了系统整体功耗,实现了高效运行和节能降耗的双重目标和双重优化。
“dNPU代表了未来大模型在PC等本地端推理的技术方向和趋势。”上述负责人强调。
端侧AI算力追求极致性价比 GPGPU站上舞台中央
随着大模型为主的生成式AI技术取得快速发展,各大PC厂商不仅在积极探索全新的AI PC形态,为推动大模型推理快速高效实现也在积极采纳和部署强劲的AI芯片。
传统AI PC解决方案是在CPU中嵌入iNPU,在运行大语言模型时,通常依赖GPU进行加速,iNPU只有在特定的场景中才能被调用。然而,GPU在处理大模型时可能会面临一些性能瓶颈,如GPU的架构虽然适合并行计算,但在处理深度学习任务时,会导致资源利用率不足或延迟较高。此外,GPU在推理阶段的功耗相对较高。
而且在群雄逐鹿的通用GPU市场中,面临着英伟达、英特尔、AMD等巨头的强大竞争,国内厂商要在重重壁垒中开辟自己的天地,需要独辟蹊径,打造全生态。芯动力敏锐地观察到,高性价比是边缘计算核心要求,且性能与TOPS不直接挂钩,不同计算阶段对性能要求不同,采用探索创新型的计算机架构的GPGPU是解决通用高算力和低功耗需求的必由之路,并已成为业界共识。
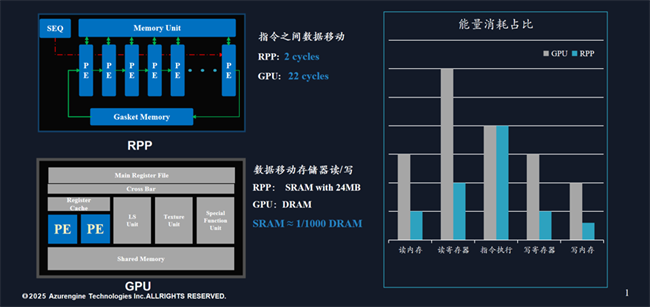
基于这一深刻洞察,芯动力推出了可重构并行处理器(RPP)架构,通过底层创新RPP架构,解决了高性能与通用性难兼以得的矛盾,利用数据流结构来避免了数据反复调用带来的效率损失。并且芯动力具有编译器、运行时环境、高度优化的RPP库,可全面兼容CUDA的端到端完整软件栈,从而实现边缘AI应用的快速高效部署。
基于上述架构和设计创新,芯动力开发了AzureBlade M.2加速卡集成的AE7100芯片,作为一款高能效GPGPU,相比传统GPU,针对神经网络的计算特点进行了优化,通过集成大量专用的计算单元(如矢量内核或神经加速器)和片上内存,可高效处理矩阵乘法和卷积等操作,从而在通用性、低时延、低功耗、低成本和快速部署等方面展现出显著优势,成为解锁端侧各大模型的关键,并成为联想AI PC落地的新动能。

(AI NOW不做大模型推理:右侧 GPU usage 和 dNPU 占用率均为 0%)

(AI NOW进行大模型推理:右侧 GPU usage 仍为 0%,dNPU 在 40% 上下波动)
“一是系统运行更丝滑。dNPU 在执行深度学习任务时,无需占用CPU、显存或GPU资源,这种设计不仅最大限度地减少了对传统GPU和显存的依赖,还通过dNPU的高效计算能力,显著提升了推理速度和整体性能,让系统运行更加丝滑流畅,大幅提升用户体验。二是低功耗优势。通过实测,在未启用AI NOW推理时,CPU的功耗仅为 7.52W,而推理时功耗上升至14.88W。dNPU的架构设计赋予其低功耗的特性,同时释放了原本由GPU占用的高功耗资源,进一步优化了系统能效,不仅实现了推理任务的高效执行,更显著降低了系统整体功耗,为用户带来性能与能效的双重优化体验。”联想工作人员介绍dNPU在处理大模型时的显著优势时表示,“因而,联想AI PC在AI计算、AI扩展、多模态交互、智能化等层面,均实现了显著的提升。”
凭借芯动力的底层创新、深厚积淀和积极拓展,不仅在AI PC领域取得了开门红,在同样广阔的泛安防/边缘服务器、工业影像/机器视觉、信号处理/医疗影像、机器人等边缘AI应用市场都已有众多应用落地,并与众多重要企业达成了战略合作。
这些市场的广阔发展前景也在徐徐展开,以安防IPC芯片市场为例,2026年全球规模将达 10.9亿美元,2025全球3D视觉识别芯片市场规模将达27亿美元;在工业影像/机器视觉市场,芯动力RPP架构GPU可对标英伟达AI算力显卡+高端FPGA;针对泛安防/边缘服务器市场,国产边缘算力芯片之外提供新的选择;在信号处理市场,更是可直接替代国外高端DSP,而更多的客户合作和应用落地。
AI芯片实现高能效低功耗 加速卡成就“全武行”
芯动力开发的AzureBlade M.2加速卡被PC巨头联想成功合作,无疑再次佐证了芯动力RPP芯片的硬核实力。

具象来看,AE7100芯片作为此款M.2加速卡的核心,是芯动力基于RPP架构自主研发的AI芯片,其尺寸仅为17mm×17mm,堪称业界最小、最薄的GPU。它不仅可以轻松放入标准M.2卡,还具备强大的计算能力,支持32Tops算力。
集成了耀眼AE7100芯片的AzureBlade M.2加速卡,更是将高性能、低功耗、小体积的优势发挥到极致。它的尺寸仅为22mm×80mm,大约半张名片大小,却拥有高达32TOPs的算力以及60GB/s的内存带宽,功耗也可以做到动态控制。
值得一提的是,为将芯片融入笔记本电脑,芯动力还革新了封装技术,采用扇出型封装,实现了无基板的FC-BGA,实现了低成本先进封装。此封装方式提升了线密度至5微米,通过三层金属线设计减小了芯片面积,降低了芯片的厚度。优化了散热与电气性能,封装后的M.2卡为AI PC提供了dNPU解决方案。
众所周知,无生态不AI。而在软件层面,AE7100实现了从底层指令集到上层驱动的全面兼容,巧妙沿用英伟达软件栈,并进行了SIMT指令集、驱动层和开发库的优化,极大地提升了开发效率与逻辑实现的直观性。由于该加速卡兼容CUDA和ONNX,能够满足各类AI应用的多样化需求,其高算力和出色的内存带宽确保了数据的高效稳定处理与传输。
对于AI PC 来说,依靠本地算力能够推动更大参数规模的模型推理亦是AI PC功能实现的关键。而芯动力的M.2加速卡已可完美支撑大模型在AI PC等设备上的流畅运行,并且适配了Deepseek、Llama3-8B、Stable Diffusion、通义千问等开源模型。
在联想将芯动力RPP架构GPGPU命名为dNPU之际,也表明dNPU正成为推动AI PC蓬勃发展的关键驱动力,不仅能够提升AI模型的推理速度、降低功耗与提升能效,还可支持多样化的AI应用,推动AI PC的创新与落地。有判断称,未来dNPU极有可能如同当下的GPU一般,成为电脑的一项常规可选配置,一旦电脑配备dNPU,用户便能在终端设备上自由地提出问题,它会凭借强大的运算能力迅速给出精准解答。
从成本角度来看,传统做法是将dNPU集成到CPU中,这会导致成本大幅增加。以某大厂处理器为例,采用3NM工艺制造,其研发与生产成本极高,导致产品价格居高不下,而大多消费者对这种高成本的配置并没有强烈需求。与之相比,将dNPU作为独立的标准化插件,具有更高的性价比和灵活性。
届时,dNPU将作为标准化插件,广泛出现在市面上所有可选择配置的电脑机型中。无论是追求极致性能的专业人士,还是日常使用电脑的普通用户,都能从中受益。它将为各类用户提供强大的AI运算支持,极大地提升电脑在如智能语音交互、图像识别处理、数据分析预测等丰富多样的人工智能应用场景下的性能表现,为用户带来更为高效、智能的使用体验 。
持续精进RPP和适配大模型 迈向芯征程
所谓众行者远。芯动力作为联想AI PC产品dNPU方案的合作伙伴,不仅是对芯动力GPGPU创新性架构的最佳背书,还为AI PC等端侧设备提供了革命性支持,解决了大模型在端侧部署的关键技术难题。这一创新技术必将加速大模型在端侧设备的普及与应用,为行业创造前所未有的价值。
不仅如此,它在工业自动化、泛安防、内容过滤、医疗影像及信号处理等众多领域都展现出了广泛的应用潜力,为边缘AI的智能化发展提供了强大的动力。
展望未来,随着大语言模型向支持多模态、多专家系统的复杂模型转变,对存储能力和计算灵活性要求更高,可重构芯片以其低功耗和高灵活性将成为极具潜力的解决方案。
而且,算力产品与各类模型的适配将成为标准化的流程,模型适配程度将直接影响应用了算力产品的AI PC在模型推理方面的表现。同时,算力厂商不能只针对特定的应用进行调优,鉴于AI PC中应用将主要以插件的形式被大模型调用,对各类大小模型以及其调用的应用进行综合适配才最为重要。因而,AI算力厂商还要持续深入建立通用、兼容的AI开发框架,并降低大模型和应用开发适配门槛。
芯动力还观察到,边缘计算作为云端算力有效补充,是AI大模型落地的必然趋势。未来边缘AI时代加速到来,将渗透至物理世界各个角落,持续打造高性价比dNPU、适配DeepSeek等新型大模型等是AI芯片厂商的“马拉松”。芯动力将继续秉承创新精神,基于RPP架构实现算力及性价比的持续提升,还将推出基于RPP集成Chiplet的8nm R36 GPU,2027年将推出更高性能的3nm R72 GPU。同时,深入提升软件适配能力,强化对更大规模模型的支持,扩展智算生态合作圈,全面推动边缘AI技术的部署与落地。
DeepSeek的技术突破,使AI更高效、更低成本地部署在端侧设备,推动AIoT持续迈向“万物智联”。我们有理由相信,基于RPP架构的GPU及后续更高性能的迭代芯片不仅是AIPC加速处理器的理想选择,在对延迟、功耗和体积有着极高要求的边缘应用中也将持续绽放光芒。